Contribution
何を支えるか
Shian Workforceに、外部Webデータを業務システムへ 継続投入するAPI基盤を供給します。
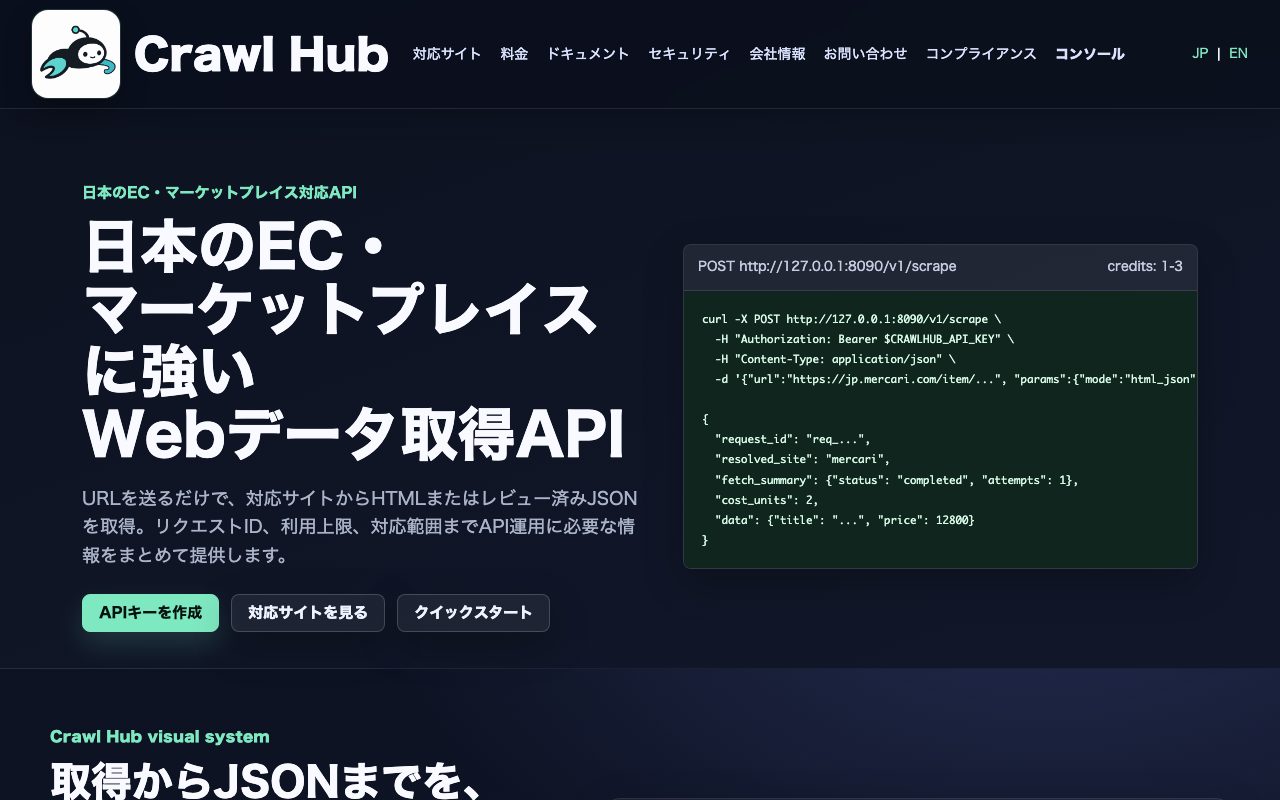
スクレイピングAPI
Webデータ取得を開発者が扱いやすいAPIへ。
Crawl HubはWebデータ取得API / Developer Platformです。 shian.spaceでは概要と活用文脈を伝え、詳細はcrawl-hub.shian.spaceへ送客します。
Role in Shian Workforce
Contribution
Shian Workforceに、外部Webデータを業務システムへ 継続投入するAPI基盤を供給します。
Implementation
Proof
Webデータ取得をAPIとDeveloper Consoleで扱える基盤。 外部情報を業務へ組み込む実装実績です。
Concept
Crawl Hubは、URL、ドメイン、ジョブを起点にWebデータ取得をAPIとConsoleで扱うDeveloper Platformです。 Shian Workforceにおいては、外部情報を継続的に業務へ取り込むAI Workforceのデータ入力基盤として扱います。
Problem
Webデータ取得が単発スクリプトや個別API利用に閉じ、業務システムへ組み込みにくい。
取得対象、ジョブ、結果、制限、監査、再実行を運用として扱いにくい。
外部情報をAI Workforceへ渡したくても、取得コスト、成功率、保守がボトルネックになる。
Solution
まず直接取得を試し、必要に応じてproxy、rendering、外部APIへfallbackします。 取得成功率とコストを見ながら、業務で使えるWebデータ取得へ寄せます。
URL取得、構造化抽出、収集ジョブ、dataset取得をAPIとして扱います。 社内ツール、SaaS、AI Agentの外部情報取得へ組み込みやすくします。
高コストAPIや手動調査で得た結果を、将来のparserやscraperの教師データとして蓄積します。 使うほど外部情報取得の資産が増える設計へ変えます。
Codex、Claude、Gemini、ChatGPT、n8nなどから使えるWebデータbackendとして設計します。 Shian Workforceが市場、競合、公開情報を参照する入口になります。
Proof
/v1/fetch
URLを投げ、Webページ取得をサービスへ組み込むためのAPI設計。
/v1/extract
HTMLやページ内容を、業務で扱える構造化データへ変換する設計。
/v1/jobs
継続取得、進捗、結果管理を運用として扱うジョブ設計。
Console
取得結果、ジョブ、利用制限を管理するDeveloper Console実装。
Use Cases
Webデータ取得をAPIとして組み込みたい
既存システムから定期取得したい
社内ツールで外部情報を扱いたい